One of the characteristics of "Problem-Oriented Languages" (POL) is that they are tiny. The language run-time provides just enough to enable a programmer to extend the language into something appropriate to the needs and terminology of the domain. This "tininess" also extends to memory usage. On a single process system the complete language and operating system can easily fit in a few kilobytes of memory. Multi-user and multi-processing features can eat up another few kilobytes here and there, but we are still only looking at a few tens of kilobytes for a whole system.
When these software techniques were first used, it was tough enough to find a computer with even this much memory. A couple of decades later, business and scientific computers were often bigger, but "home computers" with this kind of storage began to appear. I remember happily running FORTH on a Tandy TRS-80 with 16K of RAM and on my old BBC mico with 32K, for example.
Now, the bar has moved again. A few Kb (or even a few tens of Kb) of memory is commonly built-in to microcontrollers. An Arduino Uno has 32K flash and 2K SRAM.
But the Raspberry Pi is different. Despite being priced and pitched alongside microconstrollers it has massively more memory. Sure, it doesn't have as much as today's multi-gigabyte desktops, laptops, and servers, but compared with the Arduino, and with those old home machines from the 1970s and 1980s it has over 10,000 times as much memory.
That's astonishing to even think about, but it has a particular impact in the context of tiny languages and systems. We don't have to pay extra for any of that huge memory - it's there anyway, so what might we do with it?
The traditional use for spare memory in FORTH systems is as "block storage". This slices the spare memory into 1K "blocks" and uses them for data and program storage. Blocks can be saved to and loaded from permanent storage if required. While this is still a possibility, it's tough at the moment to imagine many uses which might need over 400,000 of these blocks.
This did, however, lead me to thinking about how this huge memory might be used to squeeze even more speed out of a POL language. POL languages are known for their speed as it is. The lean nature of the implementation means that they don't tend to waste much processing time with all the ceremony of objects, functions, methods, data structures and memory allocation which hides behind a typical modern programming language. But POL languages are still not quite as fast as good hand-crafted assembler code. In order to achieve their flexibility, such languages make a lot of use of building new words in terms of existing words. This has the implication that the language run-time can spend a significant proportion of its time looking up, calling, and returning from existing word definitions. In a mature system such calls can be many levels deep, requiring hundreds or even thousands of low-level words to be executed in order to run just one top-level one.
In "Programming a Problem-Oriented Language", Charles Moore writes:
The control loop must be efficient. If you count the instructions it contains, you measure the overhead associated with your program. You will be executing some very small routines, and it's embarrassing to find overhead dominating machine use.
So it occurs to me that with the bogglingly huge memory of the Raspberry Pi, much of this overhead can be eliminated by using a little of it to "unfurl" the code and eliminate the calling and returning. Consider a simple word A which calls two other words B and C. B and C in turn are implemented using machine instructions 1,2,3 and 4,5,6. In a regular program, the path of execution might look something like:
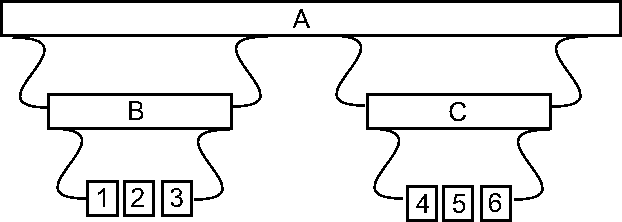
To go from the start to the end of A involves:
lookup A
push A(1)
lookup B
push B
execute 1
execute 2
execute 3
pop B
pop A(1)
next word
push A(2)
lookup C
push C
execute 4
execute 5
execute 6
pop C
pop A(2)
Even though those push, pop, next and so on are only one or two instructions each, you can see how quickly they add up.
What I am proposing is that rather than requiring A to push and call B, then push and call C, that an "unfurled" version of the low-level instructions be stored with A, as well as with B and C. In the unfurled version, calling A becomes the much simpler and quicker:
lookup A
execute 1
execute 2
execute 3
execute 4
execute 5
execute 6
If A had called B, then C, then B again, it would get all B's instructions twice:
lookup A
execute 1
execute 2
execute 3
execute 4
execute 5
execute 6
execute 1
execute 2
execute 3
This approach can be used for every word defined at every level. It acts as the complete opposite of normal programming practice which strives to reduce duplication and focus on single responsibilities, which is why it should be done transparently as the words are created. The unfurled version of each word will be stored with the word as well as its original version. To take this even further, some loops can also be unrolled, but that feels like an advanced version.
If all this rampant duplication seems profligate with storage, just remember those memory size figures. Even if this results in a ten-fold or even hundred-fold increase in program storage space. there is still masses to play with.